聲明
本文提到的 Scrapy Cloud 已經變成 Zyte,因此本文的 Scrapy Cloud 相關敘述已經不再有效。
前言:取得研究資料集
最近聽到不少擅長 Deep Learning 的朋友買了顯示卡準備自己做起研究,讓人也十分受到激勵。不過平常想自己做研究時,常常會因為沒有適當的資料集而窒礙難行。尤其不少學術資料集似乎需要由研究單位出面才能取得,使得默默無名的個人研究者深感惶恐,此時撰寫網路爬蟲蒐集資料便成為必要的麻煩。無怪乎本站的〈Scrapy 筆記〉似乎也一直很熱門。
只是平常在學校有龐大學術網路資源的支持,撰寫爬蟲還算可行。但自己一個人寫爬蟲就很辛苦了。總會擔心 IP 被阻擋要怎麼辦,還有電腦開太久,到處亂爬,會不會因此被駭客攻擊等問題。
就在最近,得知有 Scrapy Cloud 這樣方便的服務,可以用來架設自己的爬蟲,感覺相當方便。於是本文就以 PTT 為範例,紀錄利用 Scrapy Cloud 撰寫爬蟲的過程。

環境設置
這次同樣使用 pyvenv 創立虛擬環境,好安裝自己的 Python 套件:
python -m venv env
source env/bin/activate
pip install -U pip此外,也安裝 Scrapy,以及本次實驗會用到的加密套件等等。
pip install Scrapy cryptography html2textScrapy Cloud
Scrapy Cloud 其實就是 Scrapy 背後的公司 Scrapinghub 所推出的線上爬蟲服務。可以把自己寫好的爬蟲上傳到遠端的機器執行。由於 IP 偶爾就會換一次,所以可以大幅降低被阻擋的風險。在筆者撰文的當下,每個人的帳號都有一個免費的 slot (1 GB RAM) 可以用來跑爬蟲,爬下來的資料可供存放一個星期,個人使用已經相當足夠了。如果有更高的需求,也可用 $9/month 的價格購買多的 slots,或者購買可以每個 request 都使用不同 IP,大幅降低被阻擋風險的強大 proxy 服務。
創建完帳號後,首先可以在 API Key 頁面取得自己的 SH_APIKEY,到時上傳爬蟲時會用到。然後可以建立一個 project,並在 project 網址裡取得 SHUB_PROJECT_ID:
https://app.scrapinghub.com/p/<SHUB_PROJECT_ID>/jobs
最後也安裝專用的 shub 部署工具。
pip install shubBackblaze B2 Cloud Storage
Scrapy Cloud 雖然方便,不過並不支援像圖片一般大檔案的儲存。平常在學術或者企業的研究單位裡,可能有類似 S3 之類的儲存方案。不過一般小資女,小資男等等可能就沒有辦法負擔了。Backblaze B2 Cloud Storage 在筆者撰文的當下,有著 $0.005/GB/month 的低廉價格,而且上傳免費,又有 10 GB 的免費空間,而且如果只是要使用免費的部份,也不用提供付款資料,不怕被亂收錢。對於個人爬蟲的應用來說,已經相當足夠了。
註冊以後,可以在 Buckets 頁面取得 Endpoint 以及 Key Id 和 Application Key,以下稱為 B2_ENDPOINT, B2_KEY_ID 以及 B2_APPLICATION_KEY,此外同時也可以創立一個 bucket 來存放檔案,以下就把這個 bucket 稱作 storage-ptt。注意雖然網頁上沒特別寫,但以下的 B2_ENDPOINT 是以 https:// 開頭。
最後可以安裝 boto3 套件,測試檔案的操作。
pip install boto3撰寫爬蟲
於是就開始撰寫爬蟲!
首先創立專案:
scrapy startproject ptt_crawler啟用自動連線延遲:
# <root_dir>/ptt_crawler/settings.py
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY = 5
AUTOTHROTTLE_MAX_DELAY = 60
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
像上次一樣定義一些想要抓取的項目,包含本文和推文等等,但多增加檔案的欄位 files 和 file_urls:
# <root_dir>/ptt_crawler/items.py
class PostItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
date '= scrapy.Field:()'
content = scrapy.Field()
comments = scrapy.Field()
score = scrapy.Field()
url = scrapy.Field()
file_urls = scrapy.Field()
files = scrapy.Field()
接著創立爬蟲:
scrapy genspider posts ptt.cc接著就編輯 <root_dir>/ptt_crawler/spiders/posts.py 實際撰寫爬蟲程式了。
有了上次的經驗,這次寫起來相當順利。首先設定起始的網址:
# <root_dir>/ptt_crawler/spiders/posts.py
import scrapy
class PostsSpider(scrapy.Spider):
name = "posts"
allowed_domains = ["ptt.cc"]
start_urls = ["http://ptt.cc/bbs/PC_Shopping/index.html"]
def __init__(self, *args, board_names: str = None, max_pages: str = "5", **kwargs):
super().__init__(*args, **kwargs)
if board_names is not None:
self.start_urls = [
BOARD_URL_FORMAT.format(board_name=board_name)
for board_name in board_names.split(",")
]
self._max_pages = int(max_pages)
self._pages = 0
然後照抄以前的程式,不過移除 18 歲的部份:
# <root_dir>/ptt_crawler/spiders/posts.py
from ptt_crawler.items import PostItem
class PostsSpider(scrapy.Spider):
def parse(self, response):
self._pages += 1
for href in response.css(".r-ent > div.title > a::attr(href)"):
url = response.urljoin(href.extract())
yield scrapy.Request(url, callback=self.parse_post)
if self._pages < self._max_pages:
next_page = response.xpath(
'//div[@id="action-bar-container"]//a[contains(text(), "上頁")]/@href'
)
if next_page:
url = response.urljoin(next_page[0].extract())
self.logger.warning("follow {}".format(url))
yield scrapy.Request(url, self.parse)
else:
self.logger.warning("no next page")
else:
self.logger.warning("max pages reached")
def parse_post(self, response):
item = PostItem()
item["title"] = response.xpath('//meta[@property="og:title"]/@content')[
0
].extract()
item["author"] = (
response.xpath(
'//div[@class="article-metaline"]/span[text()="作者"]/following-sibling::span[1]/text()'
)[0]
.extract()
.split(" ")[0]
)
datetime_str = response.xpath(
'//div[@class="article-metaline"]/span[text()="時間"]/following-sibling::span[1]/text()'
)[0].extract()
item["date"] = datetime.strptime(datetime_str, "%a %b %d %H:%M:%S %Y")
converter = html2text.HTML2Text()
converter.ignore_links = True
item["content"] = converter.handle(
response.xpath('//div[@id="main-content"]')[0].extract()
)
comments = []
total_score = 0
for comment in response.xpath('//div[@class="push"]'):
push_tag = comment.css("span.push-tag::text")[0].extract()
push_user = comment.css("span.push-userid::text")[0].extract()
push_content = comment.css("span.push-content::text")[0].extract()
if "推" in push_tag:
score = 1
elif "噓" in push_tag:
score = -1
else:
score = 0
total_score += score
comments.append(
{"user": push_user, "content": push_content, "score": score}
)
item["comments"] = comments
item["score"] = total_score
item["url"] = response.url
yield item
在 <root_dir> 根目錄(有 scrapy.cfg 的目錄)執行:
scrapy crawl posts -o test.jl測試確實可以抓到文章。
抓取圖片
這次的示範裡,我們只想要抓有圖片的文章,所以將程式改寫。同時為了方便起見,只抓 imgur.com 上的 .jpg & .png 圖片。
# <root_dir>/ptt_crawler/spiders/posts.py
class BeautyImagesSpider(scrapy.Spider):
def parse_post(self, response):
# ...
file_urls = response.xpath('//a[contains(@href, "imgur.com")]/@href').extract()
if file_urls:
file_urls = [
url for url in file_urls if url.endswith(".jpg") or url.endswith(".png")
]
if file_urls:
item["file_urls"] = file_urls
yield item
然後先按照 Downloading and processing files and images 的教學啟用 Files Pipeline 做測試:
# <root_dir>/ptt_crawler/spiders/posts.py
ITEM_PIPELINES = {
'scrapy.pipelines.files.FilesPipeline': 1
}
FILES_STORE = 'images'
再次在 <root_dir> 根目錄(有 scrapy.cfg 的目錄)執行:
scrapy crawl posts -o test.jl應該會看到在 <root_dir>/images/full/ 底下出現不少圖片。
假設只是要在本機上抓圖,這樣就行了,不過我們想在 Scrapy Cloud 上,把圖傳到 B2 空間,因此還得進行一些修改。
上傳 B2
首先寫好上傳的串接程式,這裡因為我主要是想抓圖,所以如果 B2 連不上就乾脆用 CloseSpider 把整個爬蟲關掉了。同時因為上傳不用用錢,獲取檔案資訊卻有限制,所以乾脆 stat_file 就讓他永遠回傳空的,反正遇到相同檔案就重新上傳就好。
# <root_dir>/ptt_crawler/spiders/pipelines.py
import logging
import boto3
from botocore.config import Config
from scrapy.exceptions import CloseSpider
from twisted.internet import threads
logger = logging.getLogger(__name__)
def get_b2_resource(endpoint: str, key_id: str, application_key: str):
b2 = boto3.resource(
service_name="s3",
endpoint_url=endpoint, # Backblaze endpoint
aws_access_key_id=key_id, # Backblaze keyID
aws_secret_access_key=application_key, # Backblaze applicationKey
config=Config(
signature_version="s3v4",
),
)
return b2
class B2FilesStore(object):
B2_ENDPOINT = None
B2_KEY_ID = None
B2_APPLICATION_KEY = None
def __init__(self, uri: str) -> None:
try:
assert uri.startswith("b2://")
buckets_and_prefix = uri[5:].split("/", 1)
if len(buckets_and_prefix) > 1:
self.bucket, self.prefix = buckets_and_prefix
else:
self.bucket = buckets_and_prefix[0]
self.prefix = None
self.b2 = get_b2_resource(
endpoint=self.B2_ENDPOINT,
key_id=self.B2_KEY_ID,
application_key=self.B2_APPLICATION_KEY,
)
self.c = self._get_b2_bucket()
except (AssertionError, Exception) as e:
logger.exception(e)
raise CloseSpider("could not initialize B2")
def stat_file(self, path, info):
return {}
def _get_b2_bucket(self):
return self.b2.Bucket(self.bucket)
def _upload_file(self, buf, file_name):
self.c.upload_fileobj(buf, file_name)
def persist_file(self, path, buf, info, meta=None, headers=None):
"""Upload file to B2 storage"""
if self.prefix:
key_name = os.path.join(self.prefix, path)
else:
key_name = path
buf.seek(0)
return threads.deferToThread(self._upload_file, buf=buf, file_name=key_name)
緊接著我們修改原本 scrapy 的 FilesPipeline 變成 EncryptedFilesPipeline。目的是為了讓他支援加密以及我們的 B2FilesStore。
之所以要加密的原因是為了怕鄉民上傳一些奇怪的圖片導致我們抓到怪圖上傳,可能造成停權之類的奇怪後果。
# <root_dir>/ptt_crawler/spiders/pipelines.py
from cryptography.fernet import Fernet
from scrapy.pipelines.files import FilesPipeline
from scrapy.utils.misc import load_object
class EncryptedFilesPipeline(FilesPipeline):
# ...
def __init__(self, store_uri, download_func=None, settings=None):
super().__init__(store_uri,
download_func=download_func,
settings=settings)
cls_name = "EncryptedFilesPipeline"
resolve = functools.partial(self._key_for_pipe,
base_class_name=cls_name,
settings=settings)
encryption_key = settings.get(resolve('FILES_ENCRYPTION_KEY'))
if encryption_key is not None:
self.cipher = Fernet(encryption_key)
else:
self.cipher = None
@classmethod
def from_settings(cls, settings):
cls.STORE_SCHEMES = cls._load_components(settings, 'FILES_STORES')
b2store = cls.STORE_SCHEMES['b2']
b2store.B2_ENDPOINT = settings["B2_ENDPOINT"]
b2store.B2_KEY_ID = settings["B2_KEY_ID"]
b2store.B2_APPLICATION_KEY = settings["B2_APPLICATION_KEY"]
store_uri = settings['FILES_STORE']
return cls(store_uri, settings=settings)
@staticmethod
def _load_components(settings, setting_prefix):
conf = without_none_values(settings.getwithbase(setting_prefix))
d = {}
for k, v in conf.items():
try:
d[k] = load_object(v)
except NotConfigured:
pass
return d
def file_downloaded(self, response, request, info):
path = self.file_path(request, response=response, info=info)
if self.cipher is not None:
buf = BytesIO(self.cipher.encrypt(response.body))
else:
buf = BytesIO(response.body)
checksum = md5sum(buf)
buf.seek(0)
self.store.persist_file(path, buf, info)
return checksum
接下來可以在 <root_dir>/ptt_crawler/settings.py 填入以下設定:
# <root_dir>/ptt_crawler/settings.py
ITEM_PIPELINES = {'ptt_crawler.pipelines.EncryptedFilesPipeline': 1}
FILES_STORES = {
'': 'scrapy.pipelines.files.FSFilesStore',
'file': 'scrapy.pipelines.files.FSFilesStore',
's3': 'scrapy.pipelines.files.S3FilesStore',
'b2': 'ptt_crawler.pipelines.B2FilesStore',
}
然後填入對應的密鑰做測試,不過測試完這些設定還是不要直接寫在檔案裡比較好。
# <root_dir>/ptt_crawler/settings.py
FILES_ENCRYPTION_KEY = '<YOUR_ENCRYPT_KEY>'
FILES_STORE = 'b2://storage-ptt/ptt-posts/images/'
B2_ENDPOINT = '<B2_ENDPOINT>'
B2_KEY_ID = '<B2_KEY_ID>'
B2_APPLICATION_KEY = '<B2_APPLICATION_KEY>'
其中 storage-ptt 是在 B2 上創建的 bucket 名稱,後面的 ptt-posts/images/ 則是自行指定要存放圖片的根目錄。
而檔案加密的密鑰 YOUR_ENCRYPT_KEY 可以這樣產生:
from cryptography.fernet import Fernet
Fernet.generate_key()
加密完的檔案可以這樣解密:
from cryptography.fernet import Fernet
cipher = Fernet('<YOUR_ENCRYPT_KEY>')
with open('<INPUT_PATH>', 'rb') as infile, open('<OUTPUT_PATH>', 'wb') as outfile:
outfile.write(cipher.decrypt(infile.read()))
再次在 <root_dir> 根目錄(有 scrapy.cfg 的目錄)執行:
scrapy crawl posts -o test.jl應該會看到在 B2 裡出現不少加密檔案。
部署到 Scrapy Cloud
最後的部署,首先新增相依檔案 requirements.txt:
boto3
cryptography
html2text
再新增設定檔 scrapinghub.yml:
projects:
default: <PROjECT_ID>
stacks:
default: scrapy:1.3-py3
requirements_file: requirements.txt
接著將整個資料夾的相關程式碼和設定檔都 commit 到 git repository 裡。然後在該資料夾執行:
shub login
shub deploy輸入相應的 SH_APIKEY 即可上傳。
最後則在 project 的 spiders settings https://app.scrapinghub.com/p/<SHUB_PROJECT_ID>/job-settings/standard 裡,把各種密鑰輸進去:
FILES_ENCRYPTION_KEY = '...'
FILES_STORE = '...'
B2_ENDPOINT = '...'
B2_KEY_ID = '...'
B2_APPLICATION_KEY = '...'
如此就行了!可在 Dashboard 執行上傳的爬蟲。
定期上傳抓取文章到 B2
Scrapy Cloud 也支援排程執行,所以可以每天都到板上抓圖。然而雖然做完以上步驟就會把下載的圖片上傳到 B2,可是抓取的文章還是在 Scrapy Cloud 裡頭。幸好 Scrapy Cloud 也提供定期執行自訂 script 的功能。所以我們也可以另外寫個程式把抓好的文章上傳到 B2 上。
由於 script 不像 spider 會自動讀取 project settings,我們先自行寫一個讀取的函式,這樣就可以在 script 裡讀取在 Scrapy Cloud 上設定的參數:
# <root_dir>/ptt_crawler/utils.py
import json
import os
from scrapy.utils.project import get_project_settings
def get_shub_project_settings():
settings = get_project_settings()
shub_settings = json.loads(os.environ.get('SHUB_SETTINGS', '{}'))
settings.setdict(
shub_settings.get('project_settings', {}),
priority='project')
return settings
除此之外也順便新增一些方便處理 B2 上傳的函式:
# <root_dir>/ptt_crawler/utils.py
from io import BytesIO
def split_bucket_prefix(uri):
return uri[5:].split('/', 1)
def upload_file(bucket, file_name, content):
with BytesIO() as source:
source.write(content)
source.seek(0)
bucket.upload_fileobj(source, file_name)
最後就可以實際實做抓取資料的程式了,首先定義執行參數。
新增的 project settings 包含:
<SH_APIKEY>: 就是之前提到的 Scrapy Cloud 的 API Key<SHUB_PROJECT_ID>: 本次部屬到 Scrapy Cloud 的 project ID<ITEMS_STORE>: 儲存文章的地點,例如b2://storage-ptt/ptt-posts/items/
同樣在 project 的 spiders settings https://app.scrapinghub.com/p/<SHUB_PROJECT_ID>/job-settings/standard 裡,把他們輸進去。
另外可以指定要抓取的 spider 名稱,以本例來說,只有 posts 一種。--delete 參數則是指定抓取完後,是否要把 Scrapy Cloud 上對應的 job 順便刪除,以免下次重複上傳。
# <root_dir>/ptt_crawler/bin/upload_items.py
import argparse
from ptt_crawler.utils import get_shub_project_settings
def parse_args():
settings = get_shub_project_settings()
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument("--api-key", default=settings.get("SHUB_APIKEY"))
parser.add_argument(
"--project-id", type=int, default=settings.get("SHUB_PROJECT_ID")
)
parser.add_argument("--b2-endpoint", default=settings.get("B2_ENDPOINT"))
parser.add_argument("--b2-key-id", default=settings.get("B2_KEY_ID"))
parser.add_argument(
"--b2-application-key", default=settings.get("B2_APPLICATION_KEY")
)
parser.add_argument("--b2-path", default=settings.get("ITEMS_STORE"))
parser.add_argument("--delete", action="store_true")
parser.add_argument("spider_name", nargs="+", help="Spider name to get info from.")
args = parser.parse_args()
assert args.b2_path.startswith("b2://")
return args
if "__main__" == __name__:
main(**vars(parse_args()))
最後則是主程式,先用 ScrapinghubClient 列出需要處理的 jobs。
# <root_dir>/ptt_crawler/bin/upload_items.py
from scrapinghub import ScrapinghubClient
def main(api_key, project_id, spider_name, b2_account_id, b2_application_key,
b2_path, delete):
# ...
client = ScrapinghubClient(api_key)
project = client.get_project(project_id)
for name in spider_name:
spider = project.spiders.get(name)
job_list = spider.jobs.list(state="finished")
keys = []
for job in job_list:
if "items" in job and job["items"] > 0:
keys.append(job["key"])
緊接著,把下載的文章用 gzip 壓縮後,上傳到指定的位置上,並順便刪除上傳完的 jobs:
# <root_dir>/ptt_crawler/bin/upload_items.py
import gzip
import io
import json
import logging
import os
from b2.api import B2Api
from ptt_crawler.utils import split_bucket_prefix
from ptt_crawler.utils import upload_file
def main(api_key, project_id, spider_name, b2_account_id, b2_application_key,
b2_path, delete):
bucket_name, root = split_bucket_prefix(b2_path)
bucket = None
for name in spider_name:
# ...
if keys:
if bucket is None:
b2 = get_b2_resource(b2_endpoint, b2_key_id, b2_application_key)
bucket = b2.Bucket(bucket_name)
for key in keys:
job = spider.jobs.get(key)
if job:
out = io.BytesIO()
with gzip.GzipFile(fileobj=out, mode="w") as outfile:
for item in job.items.iter():
line = json.dumps(item) + "\n"
outfile.write(line.encode("utf8"))
content = out.getvalue()
file_name = os.path.join(root, name,
key.replace("/", "-") + ".jl.gz")
upload_file(bucket, file_name, content)
if delete:
job.delete()
logging.warning("job {} deleted".format(key))
然後在 setup.py 新增 script 的位置 bin/upload_items.py:
# <root_dir>/ptt_crawler/setup.py
# Automatically created by: shub deploy
from setuptools import setup, find_packages
setup(
name = "project",
version = "1.0",
packages = find_packages(),
scripts = ["bin/upload_items.py"],
entry_points = {"scrapy": ["settings = ptt_crawler.settings"]},
)
新增相依檔案 requirements.txt 中的一行:
scrapinghub
緊接著上傳更新的程式:
shub deploy最後就能在 Dashboard 上執行 script 了,記得在 Arguments 欄位填上 posts 等參數。
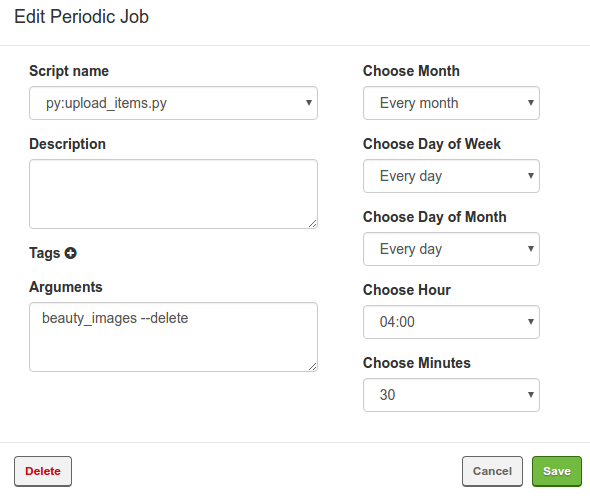
結語
如此一來就能順利的每天抓文章和圖了,其他像是偵測不要抓到同樣的文章等等的功能就請各位自行研究了。
這次實驗所用到的程式碼按照慣例放在 GitHub 上面供參考:https://github.com/shaform/ptt-crawler。
